Usando ChatGPT y Python para crear un Dashboard en PowerBI
Descubre cómo la IA simplifica tareas sin necesidad de grandes conocimientos en programación.

¿Cómo puedo ahorrar tiempo con algo que hago todos los meses? Esa es la pregunta que me hice cuando ya estaba cansado de tener que realizar distintos pasos de manera manual para generar una hoja de cálculo que resumiera toda la información relevante sobre la factura mensual de la electricidad.
Anteriormente, había diseñado una serie de pasos que tenía que seguir cada mes para obtener una hoja de cálculo con tablas y gráficos (nutridos mediante algunos archivos XLSX via Power Query) relativos a la información sobre el consumo de electricidad en casa. No obstante, era un proceso demasiado manual y que podía ser optimizado. Decidí buscar una solución que simplificara esta tarea recurrente.
Objetivo
Mis objetivos eran:
- Reducir la cantidad de trabajo manual que debía hacer cada mes en el archivo de las facturas.
- Utilizar herramientas de uso gratuito.
- Simplemente aprender y practicar cosas nuevas.
Consideraciones Previas
¿Con qué datos contamos?
La plataforma virtual del proveedor de electricidad nos facilita:
- Un archivo .XLSX con el listado de facturas y las siguientes propiedades: fecha, total a pagar, servicio y estado de la factura.
- Un archivo .CSV por cada periodo de facturación con los datos del consumo: fecha, hora, consumo, precio, coste por hora.

La estructura de carpetas
Para alojar todos los archivos de este proyecto, cree una carpeta principal y 2 subcarpetas: input y output.
Generación del Código
Debido a que no he tenido formación en informática, decidí probar hasta qué punto una herramienta como ChatGPT podría ayudarme a generar una serie de scripts que me ayudaran a automatizar distintas tareas. El lenguaje escogido para crear estos scripts fue Python, debido a su facilidad de entender y la gran variedad de librerías que tiene.
Nota: El código mostrado a continuación ha sido generado mediante IA y cuenta con pequeñas modificaciones hechas por el autor. Es muy probable que el código no esté optimizado.
Scripts
Primero: consolidate
La tarea de este script es limpiar todos los archivos CSV que se vayan metiendo en la carpeta input, debido a que estos archivos poseen una estructura que no facilita la extracción directa y sin errores de los datos del consumo diario:
- Las filas 1 a 6 poseen información sobre la factura.
- Desde la fila 7 en adelante se encuentra una “tabla” con las estadísticas de consumo, pero hay distintas filas en blanco que actual como “separador” entre cada día. Asimismo, la última fila de los datos contiene el total del consumo del periodo de facturación.
Entonces, el script debía:
- Limpiar las filas 1 a 7 (siendo la fila 7 la que contiene los encabezados de la tabla).
- Eliminar las filas en blanco.
- Eliminar la fila del total.
- Identificar los 10 primeros caracteres de la fila 1 y concatenarlos al final de cada fila.
- Extraer los datos resultantes de cada archivo CSV y anexarlos en un nuevo archivo CSV en la carpeta output.
El código generado por ChatGPT, luego de varias pruebas de ensayo y error, fue el siguiente:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
import csv
import os
def procesar_archivo(archivo_entrada, archivo_salida):
with open(archivo_entrada, 'r') as f_in:
# Leer el archivo CSV de entrada
reader = csv.reader(f_in)
data = list(reader)
# Eliminar las filas 1 a 7
data = data[7:]
# Eliminar filas en blanco
data = [fila for fila in data if fila]
# Eliminar la última fila con datos
if data[-1]:
del data[-1]
# Identificar los 10 primeros caracteres de la fila 1 y concatenarlos al final de cada fila
primeros_10_caracteres = data[0][0][:10]
data = [fila + [primeros_10_caracteres] for fila in data]
with open(archivo_salida, 'a', newline='') as f_out:
writer = csv.writer(f_out)
writer.writerows(data)
def procesar_archivos_en_carpeta(carpeta_entrada, archivo_salida):
with open(archivo_salida, 'w', newline='') as f_out:
writer = csv.writer(f_out)
for archivo in os.listdir(carpeta_entrada):
if archivo.endswith('.csv'):
archivo_entrada = os.path.join(carpeta_entrada, archivo)
procesar_archivo(archivo_entrada, archivo_salida)
# Definir las rutas de las carpetas de entrada y salida
carpeta_input = 'input'
carpeta_output = 'output'
archivo_salida = os.path.join(carpeta_output, 'consumo_consolidado.csv')
# Procesar los archivos en la carpeta de entrada y generar el archivo consolidado
procesar_archivos_en_carpeta(carpeta_input, archivo_salida)
print("Proceso completado. El archivo consolidado se ha guardado en la carpeta 'output'.")
Segundo: raw_data
El segundo script tenía que coger el archivo consolidado de la carpeta output y generar un nuevo archivo llamado “raw_data.csv” parar que sea utilizado por la herramienta que nos ayudará a generar un dashboard. Este nuevo archivo será guardado en la carpeta raíz.
Probablemente lo ideal hubiese sido unificar este código con el anterior, pero por diversas razones no conseguí que funcionara. Será una tarea a realizar en futuras mejoras.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
import csv
import os
# Ruta del archivo consolidado y archivo de salida
consolidated_file_path = "output/consumo_consolidado.csv"
output_file_path = "raw_data.csv"
# Crear la nueva fila para añadir al principio del documento CSV
new_row = ["fecha", "hora", "consumo_Wh", "precio_EUR-kWh", "coste_hora_EUR", "inicio_factura"]
# Leer el contenido del archivo consolidado
with open(consolidated_file_path, 'r', newline='') as consolidated_file:
reader = csv.reader(consolidated_file)
data = list(reader)
# Añadir la nueva fila al principio del documento CSV
data.insert(0, new_row)
# Guardar el archivo CSV con la nueva fila añadida
with open(output_file_path, 'w', newline='') as output_file:
writer = csv.writer(output_file)
writer.writerows(data)
print("Se ha creado el archivo 'raw_data.csv' con éxito.")
Tercero: invoices_raw
En este caso, el tercer script se encarga de trabajar con el archivo XLSX que contiene la información sobre el pago de las facturas.
El problema de este archivo es que las fechas de la columna 1 están puestas en formato texto y de manera literal con los meses abreviados en castellano siguiendo una estructura de DD mmm YYYY. Ej.: 20 sep 2023.
Por este motivo, si añadiésemos directamente esta información de “fechas” en nuestra herramienta de dashboards, esta no sería capaz de convertir el dato a fecha automáticamente (incluso probando con diferentes opciones de configuración regional).
Por otro lado, la columna que contiene el total pagado por cada factura, también venía en formato texto ya que incluye el símbolo del euro en cada celda. Ej.: 70,89€.

El primer problema fue resuelto generando un código que:
- Quitara todos los espacios de las celdas de la columna 1.
- Reemplazara cada abreviación de cada mes por una cadena que indicase el mes en formato numérico
/MM/. De esta manera, una vez hecha la sustitución, las celdas quedarían con una estructuraDD/MM/YYYY.
El segundo problema era fácil de solucionar: simplemente quitar el carácter del euro y sustituir las comas por puntos.
Asimismo, se tenía que eliminar la fila 1 del archivo, ya que contenía el título del archivo en una celda combinada que podría generar problemas a futuro.
Entonces, el código generado por la IA fue el siguiente:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
import openpyxl
import csv
import os
# Nombre del archivo XLSX
file_name = "Facturas.xlsx"
# Cargar el archivo XLSX
wb = openpyxl.load_workbook(file_name)
sheet = wb.active
# Lista para almacenar los datos procesados
data = []
# Función para procesar las fechas en la columna 1
def process_date(date_str):
date_str = date_str.replace(' ', '') # Eliminar espacios
date_str = date_str.replace('ene', '/01/')
date_str = date_str.replace('feb', '/02/')
date_str = date_str.replace('mar', '/03/')
date_str = date_str.replace('abr', '/04/')
date_str = date_str.replace('may', '/05/')
date_str = date_str.replace('jun', '/06/')
date_str = date_str.replace('jul', '/07/')
date_str = date_str.replace('ago', '/08/')
date_str = date_str.replace('sep', '/09/')
date_str = date_str.replace('oct', '/10/')
date_str = date_str.replace('nov', '/11/')
date_str = date_str.replace('dic', '/12/')
return date_str
# Iterar sobre las filas a partir de la fila 2 y procesar los datos
for row in sheet.iter_rows(min_row=2, values_only=True):
# Procesar la columna 1 (índice 0 en Python, columna A en Excel)
new_date_value = process_date(row[0])
# Procesar la columna 2 (índice 1 en Python, columna B en Excel)
new_amount_value = str(row[1]).replace(',', '.').replace('€', '')
row = list(row) # Convertir la tupla en lista para modificarla
row[0] = new_date_value
row[1] = new_amount_value
data.append(row)
# Guardar los datos en un archivo CSV
csv_file_name = "invoices_raw.csv"
with open(csv_file_name, 'w', newline='', encoding='utf-8') as csv_file:
writer = csv.writer(csv_file)
writer.writerows(data)
print(f"Se ha guardado el archivo CSV '{csv_file_name}' en la carpeta actual.")
Nota: Se instaló la librería
openpyxl.
Cuarto: time_period
Este script tenía el objetivo de obtener la fecha de inicio y la fecha de fin del periodo de facturación de las líneas 2 y 3 de los archivos CSV. Extraer estas fechas fue una necesidad para realizar ciertas relaciones en el dashboard.

El script simplemente recorre los archivos obteniendo las fechas y las agrega a un nuevo archivo en la carpeta principal, que posteriormente es utilizado para relacionar cada pago con su periodo de facturación (ya que el archivo XLSX de Facturas indica solamente la fecha de cobro de la factura).
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
import os
import csv
def process_csv_files():
input_folder = 'input'
output_file = 'time_period.csv'
# Lista para almacenar las filas procesadas
processed_rows = []
# Obtener la lista de archivos en la carpeta de entrada
files = os.listdir(input_folder)
# Agregar la fila inicial al archivo procesado
processed_rows.append(['inicio_factura', 'fin_factura'])
for file_name in files:
input_file_path = os.path.join(input_folder, file_name)
# Leer el archivo CSV
with open(input_file_path, 'r', newline='') as csv_file:
csv_reader = csv.reader(csv_file)
rows = list(csv_reader)
# Obtener los últimos 8 caracteres de la fila 2 y fila 3
start = rows[1][-1][-10:]
end = rows[2][-1][-10:]
# Concatenar start y end
time_period = [start, end]
# Agregar a la lista de filas procesadas
processed_rows.append(time_period)
# Escribir las filas procesadas en el archivo de salida
with open(output_file, 'w', newline='') as csv_output:
csv_writer = csv.writer(csv_output)
csv_writer.writerows(processed_rows)
print(f"Se han procesado {len(files)} archivos. Se ha creado el archivo '{output_file}'.")
if __name__ == "__main__":
process_csv_files()
Quinto: execute
Este script simplemente ejecuta en orden los demás scripts.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
import os
import shutil
# Eliminar archivos existentes en la carpeta "output"
output_folder = "output"
for file_name in os.listdir(output_folder):
file_path = os.path.join(output_folder, file_name)
try:
if os.path.isfile(file_path):
os.unlink(file_path)
elif os.path.isdir(file_path):
shutil.rmtree(file_path)
except Exception as e:
print(f"No se pudo eliminar {file_path}. Error: {e}")
# Ejecutar el script "consolidate.py"
print("Ejecutando consolidate.py...")
os.system("python consolidate.py")
# Ejecutar el script "raw_data.py"
print("Ejecutando raw_data.py...")
os.system("python raw_data.py")
# Ejecutar el script "invoices_transform.py"
print("Ejecutando invoices_transform.py...")
os.system("python invoices_transform.py")
# Ejecutar el script "time_period.py"
print("Ejecutando time_period.py...")
os.system("python time_period.py")
print("Todos los scripts han sido ejecutados.")
Dashboard en Microsoft PowerBI
Una vez que el quinto script ejecuta el resto de scripts, ya se cuenta con todos los archivos CSV y XLSX procesados y necesarios para generar un dashboard automatizado.
La herramienta escogida para esto fue Microsoft PowerBI en su versión gratuita.
Transformación de Datos
Al importar los archivos generados mediante Power Query, hubo que realizar distintas transformaciones en las tablas principalmente para ordenar columnas y filas, filtrar datos nulos (en caso de que hubiesen), y añadir alguna que otra columna auxiliar sencilla para trabajar con los gráficos del dashboard.
Sin embargo, un problema importante (y comentado anteriormente) era que el archivo de las facturas contenía la fecha de cobro de la factura, mientras que el archivo de consumos tenía las fechas de todos los días de cada periodo de facturación.
Una consolidación directa de los datos de consumo nos dificultaría la tarea de asignar el precio cobrado a cada periodo de facturación. Por este motivo, escogí añadir una columna adicional en el archivo consolidado, que para cada periodo de facturación repitiese la fecha de inicio en cada una de las filas de ese periodo.
El objetivo de este paso era poder generar una columna de índice entre el archivo XLSX y el archivo CSV con las fechas de los periodos de inicio y fin de los periodos de facturación. De esta manera, tendríamos una clave primaria en ambas tablas.
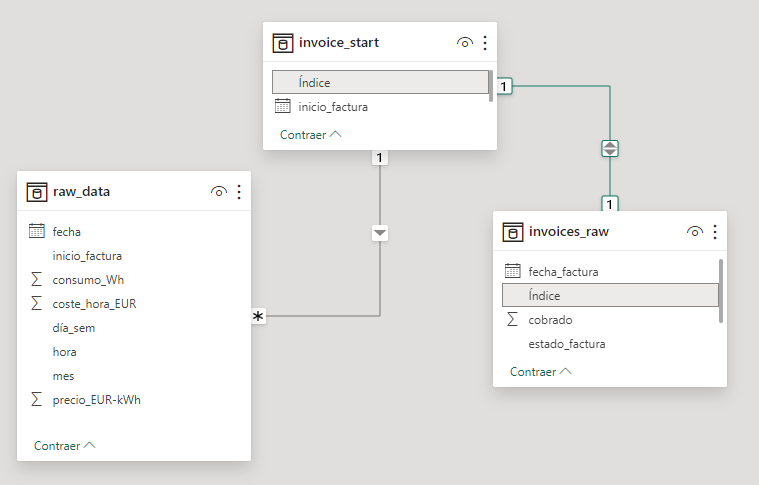
Consideración Adicional: Los periodos de facturación no coinciden con el inicio del mes, sino que inician aproximadamente entre los días 15 y 20. Lo que generaba problemas adicionales a la hora de trabajar con las tablas del dashboard.
Resultado
El resultado fue un dashboard con información interesante sobre el consumo en cada periodo de facturación y el pago efectuado.

Por otro lado, he comprobado que el código generado por IA puede ayudar a automatizar tareas sencillas generando código en un determinado lenguaje de programación y adaptado para personas sin formación, pero con algunas nociones básicas necesarias para su ejecución.

Asimismo, y como futuras líneas de mejora, lo ideal sería conseguir hacer que el código sea más simple y, quizás, unificar uno o más scripts en uno solo para ahorrar espacio. Evidentemente, esto será posible a medida que siga aprendiendo a cómo utilizar Python.
Por último, también sería interesante replicar gran parte de este proyecto utilizando las herramientas propias de análisis de datos proporcionadas por librerías de Python o el lenguaje R.